网站收录属于Technical SEO的领域。因此,有些缺乏技术知识的SEO小伙伴们会非常怕遇到这个问题。但实际上,只要我们对其中的关键概念有所理解,处理网站收录的问题就不再是什么难题。在这篇文章中,我们将先了解Google收录一个页面的过程以及其中的几个核心概念,帮助你对Google的收录过程有一个基本的了解。在本周后续的文章中,我们将继续深入地讲解如何加快Google的收录以及如何解决Google收录中遇到的一些问题,敬请期待。
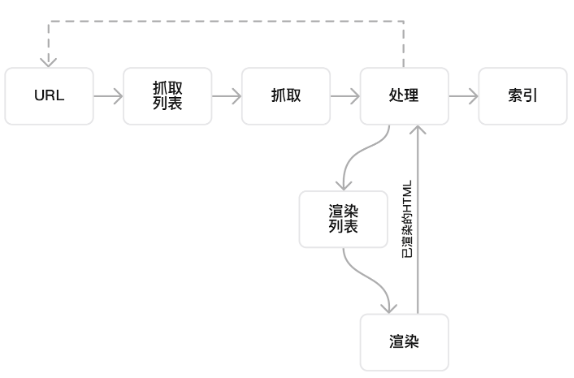
很多SEO小白会认为网站收录对于Google来说就是一下子的事情。实则不然,Google在收录一个页面之前,经过了发现-爬行-抓取-处理-索引等步骤,其中爬行、抓取、索引及收录这四个概念构成了网站收录的基础。理解它们不仅有助于你提高网站的收录量,而且也能帮助你解决可能出现的技术问题。下面,我们就来详细了解一下这个过程以及涉及的概念。1. 发现 (Discovery)
Google 主要通过网页上的链接发现新的页面。当 Google 的爬虫(也称为 Googlebot)访问一个页面时,它会抽取页面上的所有链接,并将这些链接添加到其待爬队列中。网站所有者可以使用 Sitemaps 告诉 Google 哪些页面应该被爬取和索引。Sitemap 是一个 XML 文件,列出了网站上的所有重要页面,使得 Googlebot 更容易发现它们。2. 爬行/爬取 (Crawling)
Googlebot 会定期访问网站,检查新页面或旧页面的更新。这个过程被称为“爬取”。为了决定何时和频繁地爬取某个网站,Googlebot 会考虑多种因素,例如网站的大小、服务器的速度、页面的更改频率等。网站所有者可以使用robots.txt 文件来控制 Googlebot 如何爬取其网站。例如,他们可以指定不希望 Googlebot 爬取的页面。3. 抓取 (Fetching)
抓取是爬虫从网站上获取页面内容的过程。这意味着爬虫会下载你网站上的页面,以便进一步的分析和处理。如果页面无法被抓取,那么搜索引擎就不能对其进行分析,也就无法进行后续的索引。4. 索引 (Indexing)
一旦页面被爬取和处理,它会被加入到 Google 的索引中。索引是一个巨大的数据库,存储了 Googlebot 爬取的所有网页的信息。只有索引的页面才会在 Google 搜索结果中显示。不是所有被爬取的页面都会被索引,例如,页面质量太低或被判断为 Spam 的页面可能不会被索引。5. 排序 (Ranking)
当用户在 Google 中进行搜索时,Google会从其索引中检索相关页面,并根据多种因素对其进行排序,以确定其在搜索结果中的位置。排序的因素包括页面的相关性、权威性、用户体验等。Google 使用几百个因素来确定页面的排名。
1. 直接搜索
你只需要在谷歌通过site命令,加上你的网站或者页面url。例如,如果您想查询www.example.com/mypage.html是否已被Google收录,您应输入site:www.example.com/mypage.html。如果能出现结果,那么代表你这个页面已经被成功收录了。【这种方法可以检查任意页面】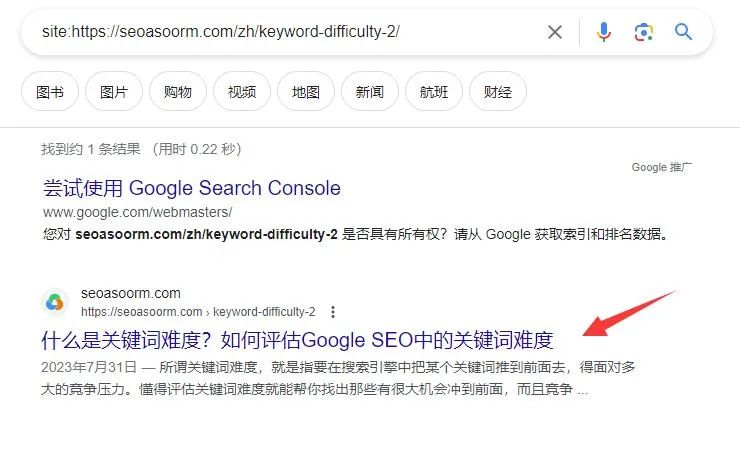
2. Google Search Console
打开GSC添加你的网站。通过这个最官方和权威的后台,你能直接看得到你自己的网站的收录情况。【这种方法只可以看自己网站的收录情况,你不能看到别人网站上的内容有没有被收录】
在Google Search Console顶部,还有一个工具叫做“URL检查工具”。如何你想检查某个具体的网页是否被收录,你可以输入您想要检查的URL,这个工具将会告诉您这个网页的收录状态和是否有任何索引问题。

理解Google收录的页面的过程是后续解决遇到的Google收录问题的重要一环。如果你的网页没有被收录,你就需要进一步去了解它是在发现、爬行、抓取还是索引环节出了错。在不同的环节出了错,有不同的应对方式。我将在后续的文章中提供详细方案,敬请期待。
【版权与免责声明】如发现内容存在版权问题,烦请提供相关信息发邮件至 lnkj@3173.top
,我们将及时沟通与处理。 本站内容除了3117站长服务平台( www.3117.cn )原创外,其它均为网友转载内容,涉及言论、版权与本站无关。